As AI/ML engineers, we are often tasked with the challenge of transforming cutting-edge research into scalable, reliable systems. Large Language Models (LLMs) offer powerful capabilities, but deploying them in real-world scenarios demands an intricate blend of architecture and pragmatism. In this discussion, we will navigate the intricate process of transitioning from simple prompts to robust, production-ready systems.
Building LLM systems extends far beyond a theoretical exercise. It involves scrutinizing model behavior under diverse conditions, integrating seamlessly with existing infrastructure, and preparing for unforeseen challenges. Here, we explore key strategies and potential pitfalls in creating systems that are not only functional but resilient.
This comprehensive guide aims to shed light on the realities of deploying LLMs, offering a blend of architectural wisdom and practical insights. We’ll delve into architectural choices, performance considerations, trade-offs, and the importance of balancing innovation with reliability.
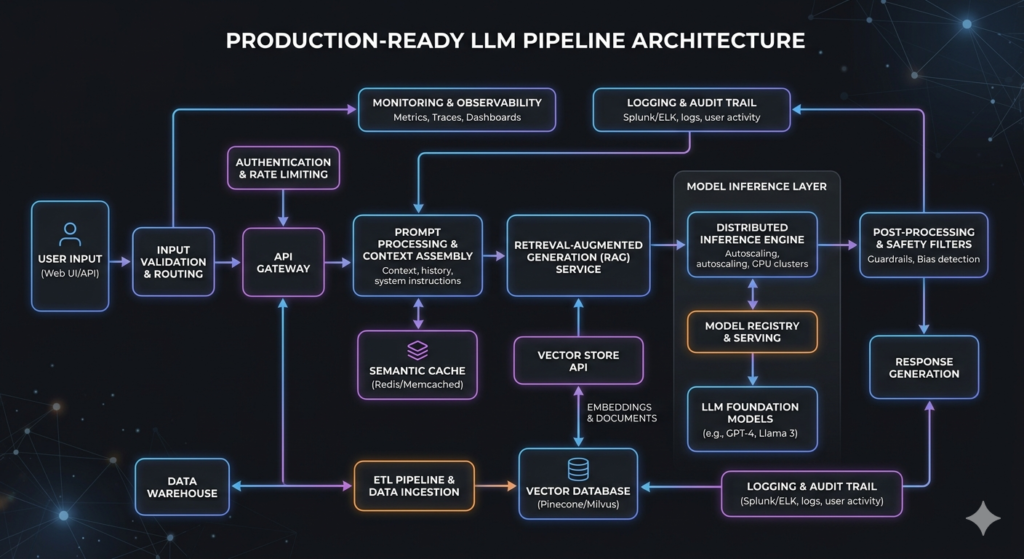
Understanding System Requirements
Every successful LLM system begins with a clear understanding of system requirements. It’s imperative to assess not only the goals but also the constraints: latency, scalability, and integration demands. Here are key aspects to consider:
Understanding these requirements guides architecture and helps identify potential performance bottlenecks early on.
Challenges and Trade-offs
When deploying LLMs, one must balance performance with resource constraints. This balance often involves making difficult decisions that impact system behavior and efficiency.
“In the relentless pursuit of performance, remember that simplicity often breeds resilience.” – Unknown
Performance Optimization Tactics
Efficiency is paramount in LLM systems. Employing strategies to optimize performance can vastly enhance system usability and sustainability.
Ensuring System Reliability
Reliability is a cornerstone of any real-world system. It’s crucial that LLMs perform predictably under diverse conditions. Here’s how to build a resilient architecture:
Firstly, prioritize redundancy. Implement fallback mechanisms in case of model failures. Secondly, maintain comprehensive logging to swiftly address issues. Finally, leverage continuous integration and deployment for regular updates and testing.
Incorporating these strategies enables systems to adapt and thrive, ensuring longevity and effectiveness in production environments.

